Today I decided to give credit and a special thank you to a lot of people in the SQL community whom have either helped me directly or indirectly with their knowledge and skills and most importantly their willingness to share back with the community.
So who do I look to for expert reliable sources for all things SQL Server. Let me start with my favorite trainers who blog. Without advanced training I would not have the skill set I have today. You can learn a lot on the job and my first DBA job lasted 6 years, covered 5 different database technologies across a few hundred servers. You can learn how to firefight well in that environment, but you rarely get a chance to hone your skills in one area. That is where training comes in. It is easy to get caught up in the day to day tasks of your particular job, and loose sight of what is new and changing. SQL Server has a lot of features that may not be applicable to your current job, but important to other jobs you may want to pursue in the future.
My first great training was Kalen Delaney, in Portland OR a few years ago, shortly after SQL 2005 had come out. The class blew my mind. Literally, I went in to the class feeling pretty competent in my skills and came out feeling very humble, and with a huge list of things I wanted to fix, change, and improve in my current job. In addition it made me want to know more and keep up with the changing technology. For that I thank Kalen and refer to her blog often as a great resource!
Kalen Delaney
http://sqlblog.com/blogs/kalen_delaney/default.aspx
As a side note I had the privilege of taking her internals class a second time when SQL 2008 first came out, it wasn't in person, but still was excellent, and I highly recommend her trainings.
Last year was the first time I had the pleasure and opportunity to take a course from Kimberly Tripp and Paul Randal. Wow, what a fantastic training. By the time I took their class I had been a production DBA for 6 years with lots of training, and was supporting over 2000 databases on more than 170 servers. I felt I had a pretty good understanding of all things SQL. My first surprise was that their was no computers or labs, it was more reminiscent of a graduate school class, with lecture, and discussion and some demonstration. It was fantastic, every day you felt like your brain had just ran a marathon. I learned a lot and tuned what I already knew even more. The networking was fantastic as well. I am very excited I get to go back for the second Immersion Event this August.
Kimberly Tripp
http://www.sqlskills.com/blogs/kimberly/
Paul Randal
http://www.sqlskills.com/blogs/paul/
Ok, I haven't taken a class from Brent, but I hear that the SQL Cruise is pretty awesome. I have met him once and he's a really nice guy. His social influence in the SQL Server realm is incredible and I have used his blog on many occasions.
Brent Ozar
http://www.brentozar.com/
I've been to a couple of Buck's presentations and he is a fantastic presenter, his blog is great too. Lots of good DBA administration stuff there, great ideas. In fact, one of Buck's talks got me started on tracking performance baselines for all of my systems.
Buck Woody
http://blogs.msdn.com/b/buckwoody/
In the category of I've never met, but am very grateful that they share their knowledge with the community, here are a few of my favorites. There are others too, but I use Glen and Ola's scripts all the time. Fantastic stuff.
Ola Hallengren
http://ola.hallengren.com/
Glen Berry
http://sqlserverperformance.wordpress.com/
Erland Sommarskog
http://www.sommarskog.se/index.html
Michelle Ufford
http://sqlfool.com/

Technical and practical musings of a SQL Server DBA
Thursday, July 7, 2011
Wednesday, June 22, 2011
More fun with Management Data Warehouse
Management Data Warehouse (MDW) really is a cool feature that was added to SQL server in 2008. While there are some issues, and the default out of the box setup might kill you on disk space and activity if you have a lot of instances sharing the same MDW, overall it is a great resource with tons of potential.
Similar to the canned reports that come with SQL Server Management Studio for database and instance details, there are canned reports that come with the setup of the MDW.
The Management Data Warehouse Overview report has three columns with links to the reports for Server Activity, Query Statistics, Disk Usage for each server you have collectors defined for.

A closer look at the Query Statistics History report gives a great overview of the top 10 queries for CPU, Duration, Total I/O, Physical Reads, and Logical Writes. You can adjust the slider at the top for a particular time range you are interested as well.

These reports are great for looking at performance over time and identifying queries that could be improved. However, I wanted to know more information and see where in the MDW the data for this graph is stored. It turns out there is a very handy stored procedure in the MDW called. [snapshots].[rpt_top_query_stats] that queries the snapshots.query_stats, core.snapshots, and snapshots.notable_query_text to get some very useful data.
The procedure takes an instance name, start time, end time, time window size, time interval (in minutes), the order by criteria (CPU,Physical Reads,Logical Writes, I/O, and Duration) and Database name.
So rather than write my own code to do the same thing I just created a new copy of this stored procedure and tweaked it a bit. instead of top 10 I changed it to be top 100. Next I tweaked some of the parameters to make it so I could get a weekly snapshot of top 100 queries by CPU, I/O etc. Now I have my own [snapshots].[rpt_top100_query_stats] stored procedure.
Next, of course I created a new SSRS report that calls my new procedure and can send me a nice pretty email of the data on whatever schedule I choose with whatever metrics I choose.

SSRS 2008 R2 is really cool, if you haven't figured out how powerful it is, take the time to play with it a bit. There are so many great things about it and I use it on a regular basis in my position as a DBA. I know I don't use it to it's full potential, I'll leave that to the BI experts. However, having numerous metric reports is incredibly helpful to me in my job. I use SSRS for monitoring trends over time and have also used it to build reports for developers to see how their code is actually preforming, plus many more.
Similar to the canned reports that come with SQL Server Management Studio for database and instance details, there are canned reports that come with the setup of the MDW.
The Management Data Warehouse Overview report has three columns with links to the reports for Server Activity, Query Statistics, Disk Usage for each server you have collectors defined for.

A closer look at the Query Statistics History report gives a great overview of the top 10 queries for CPU, Duration, Total I/O, Physical Reads, and Logical Writes. You can adjust the slider at the top for a particular time range you are interested as well.

These reports are great for looking at performance over time and identifying queries that could be improved. However, I wanted to know more information and see where in the MDW the data for this graph is stored. It turns out there is a very handy stored procedure in the MDW called. [snapshots].[rpt_top_query_stats] that queries the snapshots.query_stats, core.snapshots, and snapshots.notable_query_text to get some very useful data.
The procedure takes an instance name, start time, end time, time window size, time interval (in minutes), the order by criteria (CPU,Physical Reads,Logical Writes, I/O, and Duration) and Database name.
So rather than write my own code to do the same thing I just created a new copy of this stored procedure and tweaked it a bit. instead of top 10 I changed it to be top 100. Next I tweaked some of the parameters to make it so I could get a weekly snapshot of top 100 queries by CPU, I/O etc. Now I have my own [snapshots].[rpt_top100_query_stats] stored procedure.
Next, of course I created a new SSRS report that calls my new procedure and can send me a nice pretty email of the data on whatever schedule I choose with whatever metrics I choose.

SSRS 2008 R2 is really cool, if you haven't figured out how powerful it is, take the time to play with it a bit. There are so many great things about it and I use it on a regular basis in my position as a DBA. I know I don't use it to it's full potential, I'll leave that to the BI experts. However, having numerous metric reports is incredibly helpful to me in my job. I use SSRS for monitoring trends over time and have also used it to build reports for developers to see how their code is actually preforming, plus many more.
Friday, March 4, 2011
Creating Custom Data Collectors SQL Server 2008 R2 Part 2 SSRS
In Part 1 I discussed creating a custom data collector based off of one of the SQL Server Management Studio (SSMS) canned reports. For Part 2 I will create a SQL Server Reporting Service (SSRS) report that runs off of the Management Data Warehouse (MDW) and queries my custom collector data to build a nice graph of my top tables.
The first thing I needed was a way to connect to my MDW from my reporting server instance. Since I wanted to set up my report to be an email subscription, which means I had to have stored credentials on my SSRS server. I created a new custom sql login on my SQL Server instance where my MDW database lived. I gave it read-only or db_datareader role on that database and then verified it and then started working on the queries I wanted to run.
In the previous post I created a new collector that created a table with stats for all the tables in my database. If I look in my MDW database I now have a new table under the custom_snapshots schema with data from my new collector.

The table now has the basic stats for the database tables being monitored. Including Schema,tablename,row_count,reserved,data,index_size, unused, the collection_time and snapshot_id (this gets incremented every time the collector runs so you can distinctly identify collections).
The following query will give me a snapshot of the top ten tables as of the last collection time.
select top 10 tablename,row_count FROM [MDW].[custom_snapshots].[table_stats] Where databasename='AdventureWorksDW2008' AND snapshot_id = (select MAX(snapshot_id) from [MDW].[custom_snapshots].[table_stats] ) order by row_count desc |
Switching gears I can now open up BIDS and create a new reporting services project. You can use the wizard if you so choose or add things manually, I won't show that here but there are plenty of sites on how to get started with SSRS. For this example I want a chart, see here for a good tutorial Tutorial: Adding a Bar Chart to a Report (Report Designer).
Next in Business Intelligence Studio (BIDS) create a new project for your MDW Reports.

Whether using the wizard or creating datasource, datasets, and reports separately the key is that I will need all three for this example. (hint: the wizard will step you through creating these three things in case you get confused).
For my datasource I want to use the readonly account I created and granted access to my MDW database earlier.

Next I create a new dataset against that datasource with my query see above.

Now I need a new report (in this case I did not use the wizard). Once I have my report area visible in design view I can add a chart. I chose Bar chart for this example.

Fill in the chart data with the appropriate columns from your data set.


I added enable scale breaks to the horizontal axis since a few tables are much larger than others so it looks nicer.

Lastly I preview the report to make sure it looks right.

Now I can deploy it to my SSRS server if I want. Once there I can setup a subscription to email the report to whomever I want on whatever schedule I want. For my final report in my case I wanted a weekly report that showed table growth over time. So I had to adjust the query and chart accordingly. It now looks like this one except or course mine has numbers and labels on it.

Creating Custom Data Collectors SQL Server 2008 R2 Part 1
With the release of SQL 2008 Microsoft introduced the Management Data Warehouse and Data Collection. This feature is a fantastic tool for DBAs and System Administrators who need to not only monitor and track system performance but also quickly troubleshoot current issues by comparing active metrics with historic metrics. It is also a very handy resource for being able to report on for management.
There are several canned reports that come with the Management Data Warehouse (MDW) in addition to the canned reports that come with SQL Server Management Studio (SSMS). However there is a lot more data and functionality in the MDW than the handful of canned reports may initially lead you to believe.
The best thing to do in my opinion, if you haven't used any of these features before is to setup a development box for your first implementation of MDW and play with it for awhile before introducing it into your environment. The default collectors keep a lot of data and the database can grow quickly also if you have lots of systems collecting to the same warehouse you can see performance issues if they all try to collect and upload at the same time.
One of the coolest things about Data Collectors and MDW is the ability to create your own Custom collectors. So how to tie this all together. Well I really like the Disk Usage by Top Tables report that comes canned in SSMS.

However I really want to be able to see this data every day over time. Also, my management would like to know how fast our system is growing and how much data we are adding. The solution....?
Well what I can do is first trace the code that runs behind the SSMS report Disk Usage by Top Tables. Once I have that query I tweak it a bit to work in the confines of the collector definition. See a couple of good links here:
http://msdn.microsoft.com/en-us/library/bb677277.aspx
http://www.sql-server-performance.com/2008/system-data-collection-reports-install/
Now I can use the T-SQL from the report to be the basis for my new custom collector, essentially running that report and storing the data over time on whatever schedule I choose. You can tweak the collection frequency, caching and uploading jobs either now or after the collector is created. Also, if you want it to be for one or many databases can be configured. Once it is created be sure to enable it and verify that the new custom_snapshots table appears in your MDW.

Ok so Part 1 was a little long, so I am breaking this up in two parts. For part 2 I'll go over the SSRS report that sends management a weekly email showing top table growth.

There are several canned reports that come with the Management Data Warehouse (MDW) in addition to the canned reports that come with SQL Server Management Studio (SSMS). However there is a lot more data and functionality in the MDW than the handful of canned reports may initially lead you to believe.
The best thing to do in my opinion, if you haven't used any of these features before is to setup a development box for your first implementation of MDW and play with it for awhile before introducing it into your environment. The default collectors keep a lot of data and the database can grow quickly also if you have lots of systems collecting to the same warehouse you can see performance issues if they all try to collect and upload at the same time.
One of the coolest things about Data Collectors and MDW is the ability to create your own Custom collectors. So how to tie this all together. Well I really like the Disk Usage by Top Tables report that comes canned in SSMS.

However I really want to be able to see this data every day over time. Also, my management would like to know how fast our system is growing and how much data we are adding. The solution....?
Well what I can do is first trace the code that runs behind the SSMS report Disk Usage by Top Tables. Once I have that query I tweak it a bit to work in the confines of the collector definition. See a couple of good links here:
http://msdn.microsoft.com/en-us/library/bb677277.aspx
http://www.sql-server-performance.com/2008/system-data-collection-reports-install/
Now I can use the T-SQL from the report to be the basis for my new custom collector, essentially running that report and storing the data over time on whatever schedule I choose. You can tweak the collection frequency, caching and uploading jobs either now or after the collector is created. Also, if you want it to be for one or many databases can be configured. Once it is created be sure to enable it and verify that the new custom_snapshots table appears in your MDW.
| Begin Transaction Begin Try Declare @collection_set_id_1 int Declare @collection_set_uid_2 uniqueidentifier EXEC [msdb].[dbo].[sp_syscollector_create_collection_set] @name=N'Table Metrics', @collection_mode=1, @description=N'Collects data about the table stats.', @logging_level=0, @days_until_expiration=730, @schedule_name=N'CollectorSchedule_Every_6h', @collection_set_id=@collection_set_id_1 OUTPUT, @collection_set_uid=@collection_set_uid_2 OUTPUT Select @collection_set_id_1, @collection_set_uid_2 Declare @collector_type_uid_3 uniqueidentifier Select @collector_type_uid_3 = collector_type_uid From [msdb].[dbo].[syscollector_collector_types] Where name = N'Generic T-SQL Query Collector Type'; Declare @collection_item_id_4 int EXEC [msdb].[dbo].[sp_syscollector_create_collection_item] @name=N'Table_Stats', @parameters=N' SELECT a3.name AS schemaname, a2.name AS tablename, DB_NAME() AS databasename, a1.rows as row_count, (a1.reserved + ISNULL(a4.reserved,0))* 8 AS reserved, a1.data * 8 AS data, (CASE WHEN (a1.used + ISNULL(a4.used,0)) > a1.data THEN (a1.used + ISNULL(a4.used,0)) - a1.data ELSE 0 END) * 8 AS index_size, (CASE WHEN (a1.reserved + ISNULL(a4.reserved,0)) > a1.used THEN (a1.reserved + ISNULL(a4.reserved,0)) - a1.used ELSE 0 END) * 8 AS unused FROM (SELECT ps.object_id, SUM ( CASE WHEN (ps.index_id < 2) THEN row_count ELSE 0 END ) AS rows, SUM (ps.reserved_page_count) AS reserved, SUM ( CASE WHEN (ps.index_id < 2) THEN (ps.in_row_data_page_count + ps.lob_used_page_count + ps.row_overflow_used_page_count) ELSE (ps.lob_used_page_count + ps.row_overflow_used_page_count) END ) AS data, SUM (ps.used_page_count) AS used FROM sys.dm_db_partition_stats ps GROUP BY ps.object_id) AS a1 LEFT OUTER JOIN (SELECT it.parent_id, SUM(ps.reserved_page_count) AS reserved, SUM(ps.used_page_count) AS used FROM sys.dm_db_partition_stats ps INNER JOIN sys.internal_tables it ON (it.object_id = ps.object_id) WHERE it.internal_type IN (202,204) GROUP BY it.parent_id) AS a4 ON (a4.parent_id = a1.object_id) INNER JOIN sys.all_objects a2 ON ( a1.object_id = a2.object_id ) INNER JOIN sys.schemas a3 ON (a2.schema_id = a3.schema_id) WHERE a2.type != N''S'' and a2.type != N''IT'' Select @collection_item_id_4 Commit Transaction; End Try Begin Catch Rollback Transaction; DECLARE @ErrorMessage NVARCHAR(4000); DECLARE @ErrorSeverity INT; DECLARE @ErrorState INT; DECLARE @ErrorNumber INT; DECLARE @ErrorLine INT; DECLARE @ErrorProcedure NVARCHAR(200); SELECT @ErrorLine = ERROR_LINE(), @ErrorSeverity = ERROR_SEVERITY(), @ErrorState = ERROR_STATE(), @ErrorNumber = ERROR_NUMBER(), @ErrorMessage = ERROR_MESSAGE(), @ErrorProcedure = ISNULL(ERROR_PROCEDURE(), '-'); RAISERROR (14684, @ErrorSeverity, 1 , @ErrorNumber, @ErrorSeverity, @ErrorState, @ErrorProcedure, @ErrorLine, @ErrorMessage); End Catch; GO |
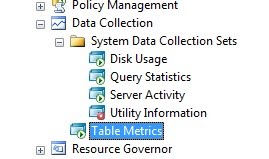
Ok so Part 1 was a little long, so I am breaking this up in two parts. For part 2 I'll go over the SSRS report that sends management a weekly email showing top table growth.
Tuesday, February 8, 2011
SSIS subsystem failed to load. The job has been suspended.
I came across a new one a month ago that I hadn’t seen before. I got a complaint from a developer that a job was hanging on one of our development servers. A consultant had set the server up before my time here, so I really didn’t know much about the install or configuration on this particular server.The error in the job history looked like this:
Step 1 of job '' (0x1077ED50A744154FFEEBC695E3C87432) cannot be run because the SSIS subsystem failed to load. The job has been suspended.
Additionally, the job had been suspended and we were unable to run it again. If we drop and recreate it, it would run, fail and suspend all over again.
Well I hadn't seen that one before so I did some high tech DBA debugging (i.e. google search).
The good news was that I got search results. The first link that I chased down was a kb article and it was regarding a similar error when you restore msdb on 2005. Well this was a 2008 R2 box that I had recently upgraded from 2008, but after some more digging I figured out that indeed the consultant who had built the instance originally had tried to duplicate another server by simply restoring msdb from that server. The key is the msdb.dbo.syssubsystems table and the msdb.dbo.sp_verify_subsystems undocumented stored procedure.
Looking at the syssubsystems table I verified that the paths listed for subsystem_dll did not exist on the server. However they did match the install path layout of another server.
To check the current file paths that SQL believes exist
select * from msdb.dbo.syssubsystems
| subsystem | subsystem_dll | agent_exe |
|---|---|---|
| TSQL | [Internal] | [Internal] |
| ActiveScripting | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLATXSS.DLL | NULL |
| CmdExec | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLCMDSS.DLL | NULL |
| Snapshot | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLREPSS.DLL | C:\Program Files\Microsoft SQL Server\100\COM\SNAPSHOT.EXE |
| LogReader | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLREPSS.DLL | C:\Program Files\Microsoft SQL Server\100\COM\logread.exe |
| Distribution | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLREPSS.DLL | C:\Program Files\Microsoft SQL Server\100\COM\DISTRIB.EXE |
| Merge | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLREPSS.DLL | C:\Program Files\Microsoft SQL Server\100\COM\REPLMERG.EXE |
| QueueReader | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLREPSS.dll | C:\Program Files\Microsoft SQL Server\100\COM\qrdrsvc.exe |
| ANALYSISQUERY | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLOLAPSS.DLL | NULL |
| ANALYSISCOMMAND | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLOLAPSS.DLL | NULL |
| SSIS | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLDTSSS.DLL | C:\Program Files\Microsoft SQL Server\100\DTS\Binn\DTExec.exe |
| PowerShell | C:\Program Files\Microsoft SQL Server\MSSQL10.QA1\MSSQL\binn\SQLPOWERSHELLSS.DLL | C:\Program Files (x86)\Microsoft SQL Server\100\Tools\Binn\SQLPS.exe |
The Fix:
use master GO --ALLOW updates EXEC sp_configure 'allow updates', 1; reconfigure with override; GO --select * from dbo.syssubsystems --(verify old values) --DELETE syssubsystems use msdb GO delete from msdb.dbo.syssubsystems GO --REPOPULATE syssubsystems exec msdb.dbo.sp_verify_subsystems 1 GO --select * from dbo.syssubsystems --(verify new values) --DISABLE updates use master GO EXEC sp_configure 'allow updates', 0; reconfigure with override; EXEC sp_configure; |
Links:
Friday, January 7, 2011
First post
First post for a new blog for the new year. I have put off blogging for a few years now, but decided it would be one of the new things I try this year. So here it goes.
The plan is to post new and old solutions to different database problems I encounter or have encountered over the years. If nothing else I will at least have one site I can go to to find that one script that I am pretty sure I wrote a few years ago, but can't seem to find it now.
I may put other stuff here too, who knows.
The plan is to post new and old solutions to different database problems I encounter or have encountered over the years. If nothing else I will at least have one site I can go to to find that one script that I am pretty sure I wrote a few years ago, but can't seem to find it now.
I may put other stuff here too, who knows.
Subscribe to:
Comments (Atom)